|
Zhenzhi Wang (王臻郅) I am currently a final-year Ph.D. candidate at MMLab in Department of Information Engineering, CUHK, advised by Prof. Dahua Lin. Before that, I received my Master's degree from Nanjing University in 2022, advised by Prof. Limin Wang, and my Bachelor's degree also from Nanjing University in 2019. My research area is computer vision, especially human-centric video generation from human pose or audio conditions. My previous research interest was video understanding and action recognition. I am open to discussions and collaborations about research, please feel free to send me emails. I am expecting to graduate in the summer of 2026 and am actively seeking internship and full-time Research Scientist opportunities in the US. Please feel free to contact me to discuss potential openings. I am also open to Research Scientist opportunities in Hong Kong, Singapore and Mainland China. Email / Google Scholar / Twitter / Github |

|
News
• 12/2025 We release TalkVerse, a large-scale audio-driven video generation dataset and model. Check out the paper and project page. |
Research |

|
TalkVerse: Democratizing Minute-Long Audio-Driven Video Generation
Zhenzhi Wang, Jian Wang, Ke Ma, Dahua Lin, Bing Zhou arXiv, 2025 arXiv / project page / code / dataset TalkVerse is a large-scale, open corpus for single-person, audio-driven talking video generation (2.3M clips, 6.3k hours) together with a 5B-parameter diffusion transformer (DiT) baseline that sustains minute-long generation with low drift and around 10x lower inference cost compared to larger commercial models. |
|
|
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Zhenzhi Wang*, Jiaqi Yang*, Jianwen Jiang*, Chao Liang, Gaojie Lin, Zerong Zheng, Ceyuan Yang, Dahua Lin. arXiv, 2025 arXiv / project page We propose a multi-person audio-driven video generation method that can handle multi-person interaction scenarios with layout-aligned audio conditions. |
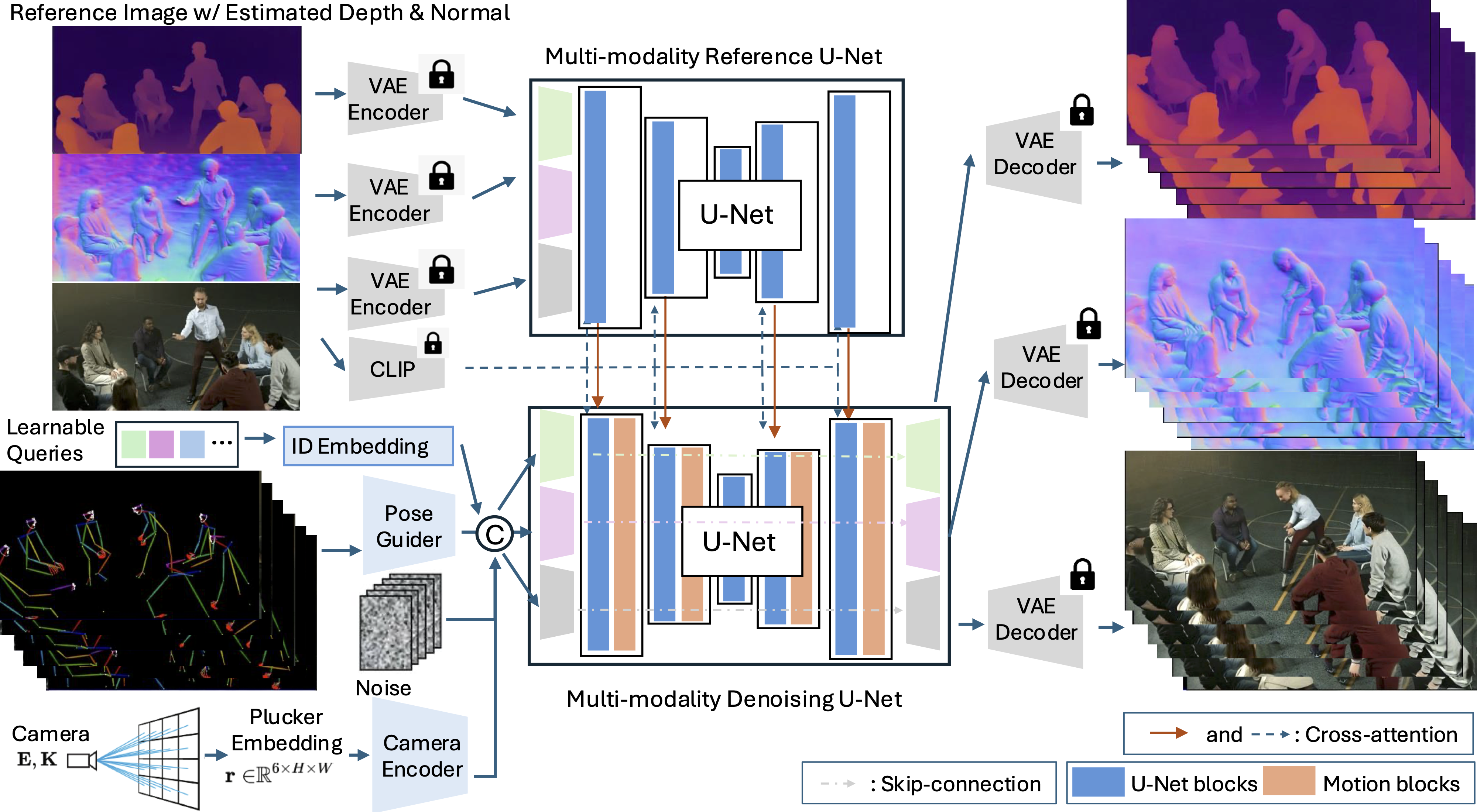 |
Multi-identity Human Image Animation with Structural Video Diffusion
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Yuwei Guo, Dahua Lin, Tianfan Xue, Bo Dai ICCV, 2025 arXiv We use identity-specific embeddings and structural learning with depth/surface-normal cues to handle complex multi-person interactions in human-centric video generation from a single image. We also contribute a dataset expansion with 25K multi-human interaction videos. |
|
|
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, Dahua Lin. NeurIPS D&B Track, 2024 arXiv / project page / code We propose HumanVid, a dataset for the camera-controllable human image animation task, and a baseline method for generating cinematic-quality video clips. As a by-product, our approach enables reproducing existing methods like Animate Anyone, alleviating the difficulty of static-camera video collection. |
|
|
InterControl: Generate Human Motion Interactions by Controlling Every Joint
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, Bo Dai. NeurIPS, 2024 arXiv / code We could generate human motion interactions with spatially controllable MDM that is only trained on single-person data. |
|
|
MatrixCity: A Large-scale City Dataset for City-scale Neural Rendering and Beyond
Yixuan Li, Lihan Jiang, Linning Xu,Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, Bo Dai. ICCV, 2023 arXiv / project page A large scale synthetic dataset from Unreal Engine 5 for city-scale NeRF rendering. |
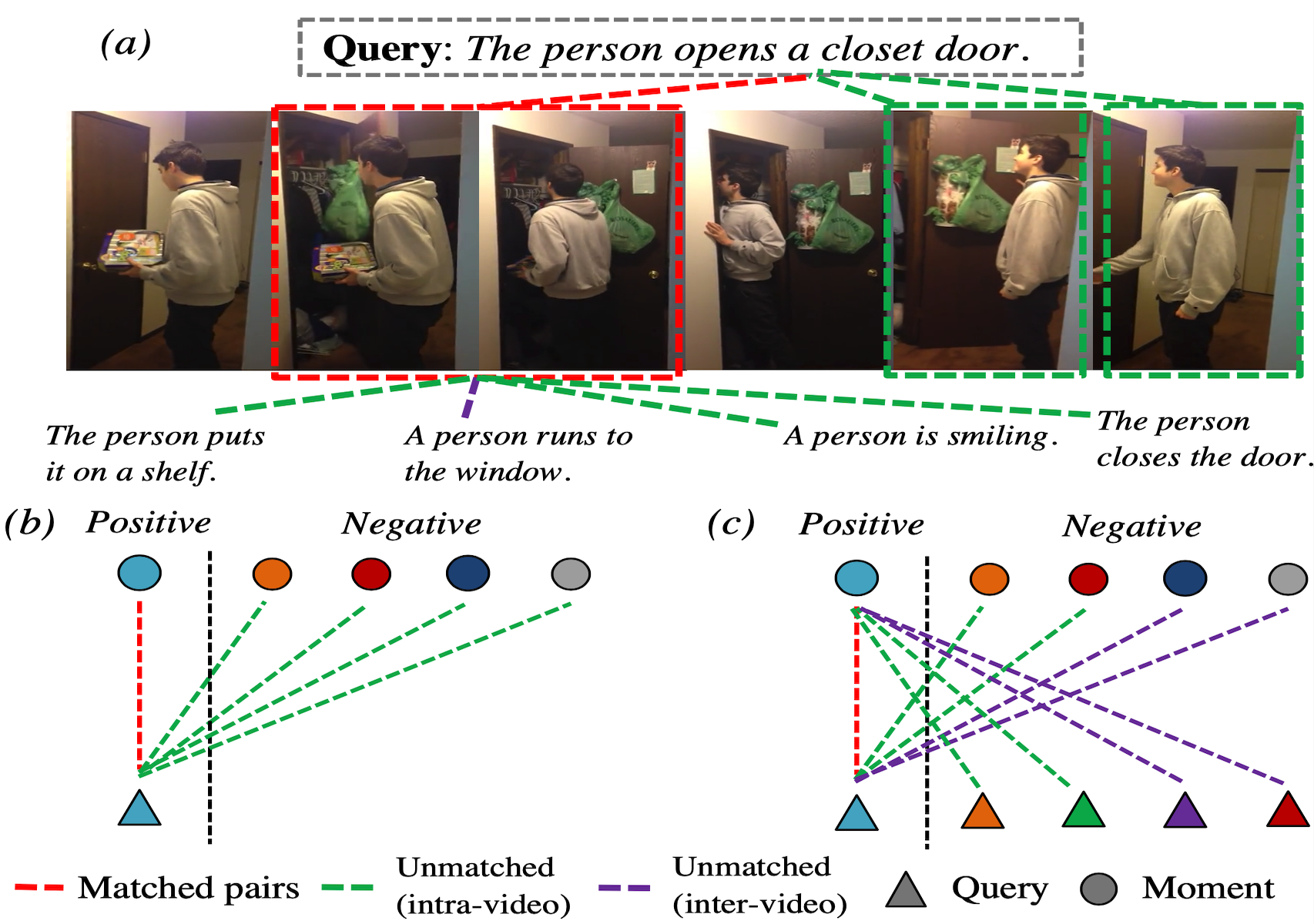 |
Negative sample matters: A renaissance of metric learning for temporal grounding
Zhenzhi Wang, Limin Wang, Tao Wu, Tianhao Li, Gangshan Wu. AAAI, 2022 arXiv / code Boost the performance of temporal grounding with contrastive learning by leveraging more negative samples. |
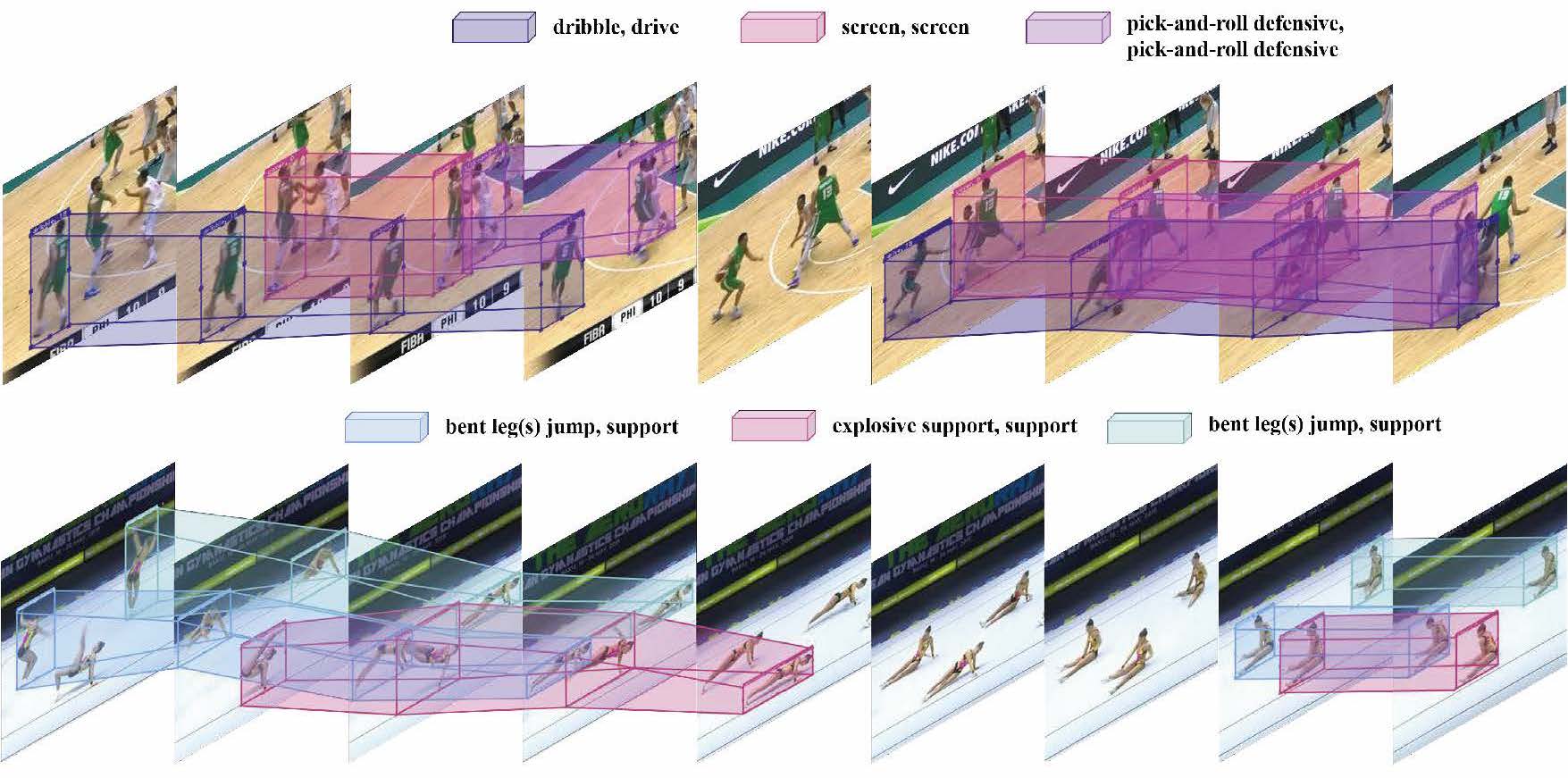 |
MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
Yixuan Li, Lei Chen, Runyu He, Zhenzhi Wang, Gangshan Wu, Limin Wang. ICCV, 2021 arXiv / code A fine-grained and large-scale spatial-temporal action detection dataset with 4 different sports, 66 action categories, 3200 video clips, and annotating 37701 action instances with 902k bounding boxes. |
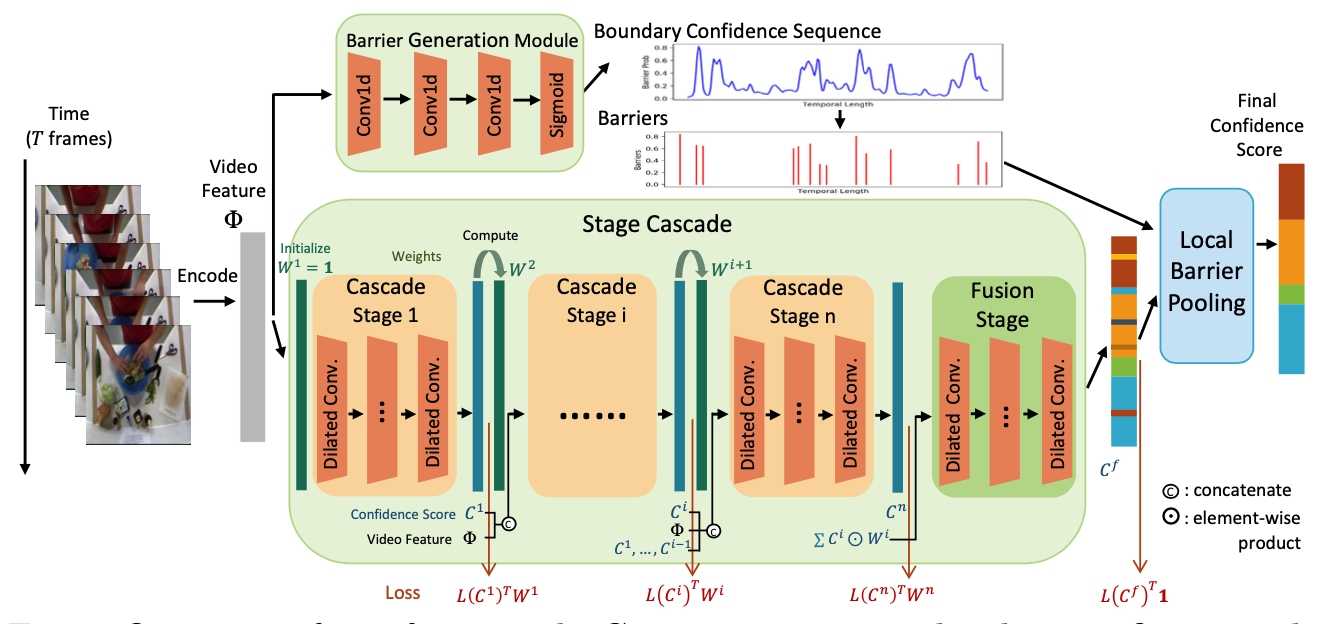 |
Boundary-aware cascade networks for temporal action segmentation
Zhenzhi Wang, Ziteng Gao, Limin Wang, Gangshan Wu. ECCV, 2020 paper / code We leverage two complementary modules to boost action segmentation performance: (1) stage cascade for boosting segmentation accuracy for hard frames (e.g., near action boundaries); and (2) local barrier pooling utilizing boundary information for smoother predictions and less over-segmentation errors. |
Professional Services
• Conference reviewer for CVPR (2024, 2023 (outstanding reviewer), 2022), NeurIPS (2024), ECCV (2024, 2022), ICCV (2023), WACV (2023). |
|
Thanks Jon Barron for sharing the source code of this website template. |